Абстракция отказоустойчивости
В этом разделе мы обсуждаем общие идеи, на которых основывается построение отказоустойчивых систем. Мы начнем с описания внешнего поведения рассматриваемых систем. Затем описывается, что означают обеспечение этими системами прозрачности отказоустойчивости и отсутствие специальных требований к поведению приложений в случае сбоя. После этого мы кратко рассмотрим проблемы, связанные с масштабируемостью таких систем. В заключение раздела мы кратко обсудим роль транзакций при формировании этих отказоустойчивых систем.
Аннотация
Надежные системы всегда основывались на ненадежных компонентах . Раньше компоненты были небольшими, такими как "зеркальные" диски (mirrored disk) или основная память с поддержкой кодов, исправляющих ошибки (Error Correcting Codes, ECC). Тогда системы разрабатывались таким образом, чтобы сбои этих небольших компонентов оставались незаметными для приложений. Потом размер ненадежных компонентов стал увеличиваться, и приложениям пришлось столкнуться с семантическимим проблемами, возникающими в результате сбоев этих компонентов.
Отказоустойчивые алгоритмы состоят из набора идемпотентных подалгоритмов. Эти идемпотентные подалгоритмы пересылают один другому состояние на границах отказов ненадежных компонентов. Тогда можно обеспечить устойчивость системы к отказу ненадежного компонента за счет перехвата управления резервным компонентом, в котором используется последнее известное состояние, и продвижение вперед происходит с помощью повторного выполнения соответствующего идемпотентного подалгоритма. Классически это делалось линейным, пошаговым образом.
По мере увеличения размеров ненадежных компонентов (от масштаба зеркального диска до масштаба системы или даже центра данных) задержки, требуемые для восстановления их состояния, становятся неприемлемыми. Это приводит к потребности в ослабленной модели отказоустойчивости. В этой модели основная система подтверждает получение заявки на выполнение работы и выполнение соответствующих действий, не дожидаясь оповещения резервной системы. В результате повышается реактивность системы, поскольку пользователи не ощущают замедления работы из-за взаимодействия основной системы с резервной.
Асинхронная поддержка состояния системы подразумевает следующее.
Все обязательства основной системы являются вероятностными. Всегда имеется ненулевая вероятность того, что вскоре после подтверждения системой некоторого требования пользователя произойдет отказ, в результате которого в резервной системе будет отсутствовать информация о соответствующем обязательстве.
Следовательно, ничто не гарантируется!
Приложения должны обеспечивать согласованность "рано или поздно" (eventual consistency) . Поскольку выполнение работы из- за отказа основной системы может застопориться и возобновиться позже, порядок выполнения работ не может гарантироваться.
Разработчики платформ, основанных на этой модели, стараются облегчить жизнь разработчикам приложений. Появляющиеся паттерны согласованности "рано или позно" и вероятностного выполнения скоро смогут предоставить разработчикам приложений способ представления требований к "ослабленной" согласованности, обеспечивая при этом доступность приложений даже при возникновении крупных сбоев. В статье также демонстрируется, что эти паттерны применимы и к периодически связываемым приложениям.
В статье описываются этапы развития этих тенденций, демонстрируются соответствующие паттерны и обсуждаются направления дальнейших исследований в области "строительства на песке".
Асинхронность и истинность
Обсудим эти осиротевшие транзакции из примера с доставкой журнала, застрявшие в чреве отказавшей системы. Они наверняка не влияют на ситуацию до тех, пор, пока отказавшая система (или центр данных) остается недоступным. Когда же эта система вновь обретет работоспособность, целью любой политики восстановления будет анализ работы, которой соответствует заключительная часть журнала, и определение того, что с ней делать! Резервная система продолжала работать, и может быть проблематично заново воспроизвести эту работу. Единственный способ сберечь эту работу состоит в том, чтобы удостовериться, что ее повторное выполнение не в исходном порядке не принесет вреда. В некоторых случаях "повисшая" работа просто отбрасывается из-за отсутствия механизма для ее воспроизведения! Это является частью неявной модели согласованности при доставке журнала без восстановления потерянной работы.
В примере с доставкой журнала мы видим редкие случаи переупорядочивания работ, когда они теряются, а потом восстанавливаются. В более общем случае мы видим независимую работу, выполняемую в отсоединенном (или слабо подсоединенном) узле, которая может быть переупорядочена, когда становится видимой другим системам, имеющим отношение к этой работе.
| Более глубокое наблюдение состоит в том, что следующие два вещи являются связанными:
переход от синхронной к асинхронной установке контрольных точек для уменьшения задержки и утрата непререкаемой истины. |
Когда у нас была централизованная машина с синхронной установкой контрольных точек, мы знали один и только один ответ в каждый момент времени. Но если допустить изолированность работы в недоступной резервной системе (бывшей до своего отказа основной системой), то истина становится неизвестной.
Благодарности
Мы хотим поблагодарить Декстера Барнеса (Dexter Barnes) и Свами Сивасубраманьяна (Swami Sivasubramanian) за их комментарии к этой статье.
в теореме CAP утверждается, что
Как отмечалось выше, в теореме CAP утверждается, что из трех свойств – Consistency, Availability и Partition-tolerance (согласованность, доступность и терпимость к разделению) можно удовлетворить любые два, но не все три сразу. Мы с этим не спорим.
Однако интересно то, что под "согласованностью" в этой теореме понимается согласованность в смысле классических ACID-транзакций (Atomic, Consistent, Isolated и Durable – атомарность, согласованность, изолированность и долговечность). Целью ACID-транзакций является создание для каждого приложения такой среды, в которой якобы имеется только один компьютер, и он не делает ничего другого при обработке данной транзакции.
Рассмотрим новые свойства ACID (или ACID2.0). Эта аббревиатура раскрывается как Associative, Commutative, Idempotent и Distributed (ассоциативность, коммутативность, идемптентность и распределенность) . ACID2.0-работа считается успешно выполненной, если каждая из ее частей выполнена
по крайней мере, один раз,
где бы то ни было в системе,
в любом порядке.
Таким образом определяется новый ВИД согласованности. Отдельные шаги выполняются в одной или нескольких системах. Приложение является явным образом устойчивым к изменению порядка работы. Оно также устойчиво к неоднократному выполнению одного и того же шага.
Заметим, что примеры 4 (корзина покупок) и 5 (обработка чеков) соответствуют этому стилю согласованности.
Дом на песке
Пэт Хелланд, Дейв Кэмпбел
Перевод: Сергей Кузнецов
Оригинал: Pat Helland, Dave Campbell. Building on Quicksand. Proceedings of the Fourth Biennial Conference on Innovative Data Systems Research (CIDR 2009), January 4-7, 2009, Asilomar, Pacific Grove, CA USA
Пэт Хелланд, Дейв Кэмпбел
Перевод: Сергей Кузнецов
Пэт Хелланд, Дейв Кэмпбел
Перевод: Сергей Кузнецов
Пэт Хелланд, Дейв Кэмпбел
Перевод: Сергей Кузнецов
Пэт Хелланд, Дейв Кэмпбел
Перевод: Сергей Кузнецов
Доставка журнала и семантика перехвата управления
Доставка журнала производится асинхронно с выдачей ответа приложению. Это, по сути, приводит к образованию окна во времени, когда выполнение работы подтверждается пользователю, но соответствующие данные еще не доставлены в резервную систему. Отказ основной системы, происходящий в течение этого промежутка времени, приведет к изоляции этой работы внутри первичной системы на неопределенное время. Резервная система будет двигаться вперед без информации об этой изолированной работе.
В большинстве случаев применения асинхронной доставки журнала это не учитывается при разработке приложений. Считается, что такое окно образуется редко, и не следует учитывать возможность отказа в этот промежуток времени. Если вдруг не повезет, то будут неприятности. К сожалению, в большинстве систем при перехвате управления требуется ручная подчистка работы, не переданной от основной системы резервной, или же эта работа просто теряется.
Дзэн и искусство согласованности "рано или поздно"
В этом разделе мы более глубоко рассмотрим понятие согласованности "рано или поздно" и обсудим, как можно создавать поддерживающие такую согласованность приложения. Мы начнем с пары примеров: системы хранения компании Amazon Dynamo и основанного на ней приложение Shopping Cart и классического банковского приложения клиринга чеков. Затем мы поговорим о приложениях, реализующих согласованность "рано или поздно", и сопоставим это с трудностями обеспечения согласованности этого вида на уровне хранения данных. Наконец, мы обсудим важность "операционно-центрического" ("operation-centric") подхода к обеспечению согласованности "рано или поздно", при применении которого операции, требуемые пользователю, регистрируются и становятся основой реализации согласованности "рано или поздно".
Еще раз про абстракцию
Итак, мы познакомились с базовой моделью отказоустойчивости и возможностью ее применения в нескольких разных системах. В первых двух примерах подверженным отказам компонентом являлся процессор, работающий в той же стойке, что и его резервный партнер. Тесная близость этих компонентов допускает практическое использование синхронного копирования состояния. В примере с доставкой журнала задержка на время передачи является недопустимой на практике, и состояние передается асинхронно. Это приводит к "отказам" механизма отказоустойчивости в центрах данных.
2Установка контрольной точки (checkpoint) – это описанный в метод управления состоянием пары процессов. Два идентичных процесса выполняются на разных процессорах, один из процессов – основной (primary), а второй – резервный (backup). Установка контрольной точки состоит в посылке от основного процесса резервному сообщения, которое описывает состояние, требуемое для отказоустойчивого функционирования.
Идемпотентность и разделяемые потоки работ
Важно обеспечивать идемпотентность одиночных операций. Это следует учитывать при разработке приложений, допускающих асинхронность, поскольку идемпотентность операций способствует отказоустойчивости и допускает слабую связанность, что, в свою очередь, позволяет снизить задержку, облегчает масштабирование и дает возможность автономной работы.
Каждая операция должна производить одно и только одно воздействие, даже если она выполняется (или просто журнализуется) в нескольких репликах. Бронирование одной комнаты в гостинице должно (с высокой вероятностью) приводить к тому, что постоялец получит в точности одну комнату. Заказ в режиме онлайн одной книги не должен (очень часто) приводить к отправке заказчику двух книг.
Чтобы это гарантировать, приложение обычно связывает с каждой работой уникальный номер, или идентификатор. Это связывание происходит на входе в систему (т.е. независимо от того, в какой реплике эта работа будет выполняться изначально). Когда запрос данной работы двигается по сети, каждая реплика может легко опознать, что уже встречала эту операцию, и не выполнять работу повторно.
Иногда поступающая работа стимулирует выполнение другой работы. Например, обработка заказа на покупку может привести к планированию доставки. Обработкой этого заказа и даже планированием доставки могут заняться, например, две реплики. При наличии уникальной идентификации заказа на покупку на входе в систему этот избыток энтузиазма со стороны реплик системы можно выявлять по мере того как информация распространяется по сети. Ниже, при обсуждении согласованности "рано или поздно" (eventual consistency) мы увидим, как это можно проделать (вероятностным образом).
Уникальный идентификатор работы ("uniquifier") играет две важные роли:
используется в качестве ключа при разделении работы в масштабируемой системе;
позволяет системе выявлять повторное выполнение одного и того же запроса; в результате работа становится идемпотентной.
Избыточное и гарантированное резервирование
Поскольку мы говорим о системах с асинхронной установкой контрольных точек, имеется некоторая вероятность, что в таких системах две реплики (или большее их число) будут выделять своим пользователям ресурсы. Поскольку иногда эти реплики будут лишены возможности общения, нам необходима политика изолированного распределения ресурсов. Имеются два подхода:
Гарантированное выделение (Over-Provisioning). При этом подходе у каждой реплики имеется фиксированное подмножество ресурсов, которые она может распределять. Если на складе имеется 1000 книг, то у каждой реплики может иметься по 500 книг для продажи. При гарантированном выделении реплика не может сделать ошибку при выделении ресурса, который в действительности выделен быть не может. С другой стороны, гарантированность выделения означает, что внутри реплик будут удерживаться избыточные ресурсы.
Избыточное резервирование (Over-Booking). В отличие от гарантированного выделения, при избыточном резервировании допускается возможность того, что разъединенные реплики время от времени будут обещать нечто такое, что они не смогут обеспечить. Из-за того, что допускается независимое резервирование ресурсов без обеспечения их строгого разделения, иногда реплики берут на себя некоторые обязательства, которые не могут выполнить. С другой стороны, иногда удастся обрабатывать запросы, которые были бы отклонены при гарантированном выделении на основе строгого разделения ресурсов.
Можно придерживаться консервативной политики и гарантировать, что НИКОГДА не придется оправдываться перед клиентами. Однако иногда это будет приводить к отказу от выполнения работы, которую можно было бы выполнить. Можно принять к выполнению работу в отсоединенной реплике без уверенности в возможности соблюдения своих обязательств. Можно динамически перемещаться между двумя этими позициями (когда между репликами имеется связь) и регулировать вероятности и возможности.
При отсутствии связи вы не знаете точного ответа и должны применять бизнес-политику, допускающую компромиссы, приемлемые для вашего бизнеса!
Коммутативность и бизнес-правила
Во многих приложениях можно сформулировать свойственные им бизнес-правила и допустить изменение порядка выполнения различых операций. Когда эти операции выполняются в раздельных системах, и порядок их выполнения может изменяться, важно соблюдать эти бизнес-правила.
К числу примеров бизнес-правил относятся следующие: "Нельзя резервировать билеты на авиарейс в объеме, более чем на 15% превышающем число мест в самолете" или "Нельзя допускать овердрафт на текущем счете".
| Депозитарные блокировки в сериализуемых базах данных
Депозитарные блокировки (escrow locking) – это схема, позволяющая повысить уровень параллелизма транзакций с сохранением их классического ACID-поведения. Если допустить наличие набора коммутативных операций (таких как увеличение и уменьшение), то можно использовать "журнализацию операций" ("operation logging”). При журнализации операций не сохраняются старое и новое значения соответствующего поля, а запись в журнале содержит данные типа "Транзакция T1 вычла $10". Если транзакцию T1 потребуется аварийно завершить, система просто увеличит значение этого поля на $10, а не будет восстанавливать его значение до выполнения данной операции. Таким образом, работа нескольких транзакций может перемежаться, пока в них выполняются только коммутативные операции. Если в какой-либо операции по отношению к данному полю выполняется операция чтения, которая коммутативной не является, она портит всю картину и останавливает параллельную работу. Депозитарные блокировки можно реализовать совместно с ограничениями, поддерживающими бизнес-правила. Рассмотрим операции увеличения и уменьшения с заданными ограничениями на минимальное и максимальное значения соответствующего поля. От системы просто требуется отслеживать эти значения и при их достижении задерживать фиксацию транзакций. Выполнение новой операции может быть задержано, если оно МОЖЕТ привести к недопустимому значению поля. У депозитарных блокировок имеется четкая семантика, поскольку они поддерживаются централизованным образом, и при этом соблюдаются ограничения бизнес-правил. |
Этот подход похож на описанный в метод депозитарных блокировок. При применении этого метода допускается выполнение коммутативных операций, если только они не нарушают ограничений системы. Депозитарные блокировки представляют собой пессимистическую схему блокировок, строго поддерживающую сериализуемое поведение транзакций. Метод депозитарных блокировок был реализован в NonStop SQL компании Tandem в конце 1980-х гг. для поддержки высокопропускных транзакций с операциями увеличения и уменьшения.
|
Операции записи в базу данных не коммутативны! Построение произвольного приложения поверх системы хранения данных препятствует переупорядочиванию операций. Желательной слабой связанности можно достичь только при использовании коммутативных операций. Операции приложения могут быть коммутативными, операции записи не коммутативны. Система хранения (т.е. операции чтения и записи) – это неудобная абстракция... |
Компьютинг и реальная действительность
В предыдущем подразделе говорилось, что гарантированное выделение ресурсов не позволяет совершить ошибку выделения ресурса, который в действительности не доступен. Это действительно так, если иметь в виду вычислительные ресурсы. К сожалению реальный мир не всегда точно моделируется на компьютерах (и это не всегда возможно).
Рассмотрим ситуацию, когда на складе имеется только один экземпляр книги, предназначенный для продажи. При использовании схемы гарантированного выделения ресурсов не возникнет никаких недоразумений со складом, и книга будет обещана заказчику. Но при подготовке книги к доставке она попадет под колеса автопогрузчика. И, несмотря на гарантированность выделения, придется извиняться перед клиентом!
Даже если компьютерные системы были бы совершенны, бизнес невозможен без извинений, поскольку непредвиденные ситуации неизбежны!
Литература
John von Neumann, Probabilistic Logics and the Synthesis of Reliable Organisms from Unreliable Components, Automata Studies, Princeton University Press (1956).
Robert M. Pirsig, Zen and the Art of Motorcycle Maintenance: An Inquiry into Values. New York, Quill. 25th Anniversary Edition, ISBN: 0688171664 (1974). Перевод на русский язык М.Немцова: Роберт М. Пирсиг. Цзэн и искусство ухода за мотоциклом: исследование ценностей
Jim Gray, Notes on Data Base Operating Systems, Lecture Notes in Computer Science (60): 393-481 Springer-Verlag (1978).
Andrea Borr, Transaction Monitoring in ENCOMPASS, Proceedings of the 7th VLDB (September 1981).
Joel Bartlett, A NonStop Kernel, Proceedings of the Eighth Symposium on Operating Systems Principles (SOSP). Pp. 22-29. December, 1981.
L. Lamport, R. Shostak, and M. Pease, The Byzantine Generals Problem, ACM Transactions on Programming Languages and Systems 4 (3): 382-401. (July 1982)
Andrea Borr, Robustness to Crash in a Distributed Database: A Non Shared-Memory Multi-Processor Approach, Proceedings of the 9th VLDB (September 1984). Also Tandem Computers TR 84.2
Jim Gray, Why Do Computers Stop and What Can Be Done About It?, Tandem Computers TR85.7
O’Neil, Pat, The Escrow Transactional Method, ACT Transactions on Database Systems (TODS), Volume 11, Issue 4 (December 1986).
Philip A. Bernstein, Vassos Hadzilacos, Nathan Goodman, Concurrency Control and Recovery in Database Systems. Addison-Wesley Longman (1987).
Pat Helland, Harald Sammer, Jim Lyon, Richard Carr, Phil Garrett, Andreas Reuter, Group Commit Timers and High Volume Transaction Systems, Proceedings of the 2nd International Workshop on High Performance Transaction Systems, also Lecture Notes in Computer Science, vol 359, Springer-Verlag, 1987.
Jim Gray and Andreas Reuter, Transaction Processing: Concepts and Techniques, Morgan Kaufmann Publishers, Inc. 1993.
Eric Brewer, Towards Robust Distributed Systems, PODC (Principles of Distributed Computing) Keynote (July 2000)
Seth Gilbert and Nancy Lynch, Brewer’s Conjecture and the Feasibility of Consistent, Available, and Partition-Tolerant Web Services, ACM SIGACT News, Volume 33, Issue 2 (June 2002).
Pat Helland, Life Beyond Distributed Transactions an Apostate’s Opinion, Conference on Innovative Database Research (CIDR) January 2007.
Pat Helland, Memories, Guesses, and Apologies, Blog entry (May 2007).
Shel Finkelstein invented the clever new acronym for ACID. Captured in private communication (September 2007).
Guiseppe DeCandia, Deniz Hastorun, Madan Jampani, Gunavardhan Kakulapati, Avinash Lakshman, Alex Pilchin, Swami Sivasubramanian, Peter Vosshall and Werner Vogels, Dynamo: Amazon's Highly Available Key-Value Store, 21st ACM Symposium on Operating Systems Principles, Stevenson, WA, October 2007.
Pat Helland, The Irresistible Forces Meet the Movable Objects, Microsoft TechEd Developers EMEA Keynote, Barcelona, Spain (November 2007).
Werner Vogel. Eventually Consistent, ACM Queue Vol. 6, Number 6. October 2008.
Wikipedia. Futures Contract.
Масштабирование и идемпотентные алгоритмы
В работе один из авторов (Хелланд) утверждает, что особого внимания заслуживают масштабируемые и распределенные приложения, создаваемые без использования распределенных транзакций. Распределенные транзакции (в особенности те, в которых используется двухфазный протокол фиксации ) делают системы нестабильными и снижают их уровень доступности. По этой причине они редко применяются в производственных системах, особенно в тех случаях, когда мененджеры ресурсов выходят за границы доверия и полномочности. В упомянутой выше статье предлагается, чтобы в масштабируемых приложениях всегда применялась некоторая дисциплина разделения данных на порции (чанки, chunk), которые всегда остаются в одном узле, даже если происходит переразделение данных. У каждого чанка имеется уникальный ключ.
При разработке отказоустойчивых систем идемотентные подалгоритмы часто рассеиваются распределенным образом по сети. В одном из наблюдаемых паттернов размещение всех этих идемпотентных подалгоритмов следует подобной дисциплине. Данные и поведение компонентов системы, управляемых такими подалгоритмами, сосредотачиваются в единственном узле, даже если требуется переразделение. Совокупные данные каждого подалгоритма идентифицируются некоторым уникальным идентификатором (называемым в "ключом"), что обеспечивает возможность их сохранения в каждый момент времени в точности в одном узле.
Медленное наступление асинхронности
В этом разделе мы увидем первый пример подтверждения поступающего запроса ДО посылки соответствующих данных в резервную копию. Это асихронная установка контрольных точек с резервной копией.
Мы начнем с очень простого обсуждения "доставки журнала" (log-shipping), при которой журнал транзакций посылается в резервную систему иногда после подтверждения пользовательского запроса. Это принципиальное изменение, глубоко влияющее на гарантии, которые обеспечиваются для пользователей.
После обсуждения доставки журнала мы проанализируем семантику перехвата управления при применении этого подхода. Затем мы обсудим, какого пересмотра нашей абстракции отказоустойчивости требует появление этой асинхронности.
Моделирование "системы"
При анализе взаимодействий с отказоустойчивой "системой" нам желательно рассматривать ее поведение в виде "черного ящка". В систему извне посылаются запросы для обработки. В прошлом эти запросы вводились пользователями с их терминалов и передавались в систему в блочном режиме. Теперь они обычно принимают форму XML, SOAP и других запросов в стиле Web.
Для обеспечения надежности эти исходящие запросы повторяются своим источником. В классическом режиме подается запрос, и если в течение установленного промежутка времени от системы не поступает ответ, то этот запрос подается повторно. Отказоустойчивая серверная система должна сделать обработку запросов пользователя идемпотентной, поскольку иначе повторяющиеся запросы временами приводили бы к повторению уже выполненной работы. На практике системы становятся идемпотентными постепенно, по мере того так разработчики начинают осознавать суть проблемы и вносят в систему соответствующие изменения.
Для поддержки этой потребности в идемпотентности либо каждый запрос сопровождается некоторым уникальным идентификатором ("uniquifier"), обеспечивающим запросам уникальность (и позволяющим связать с исходным запросом все его повторения), ЛИБО для обеспечения того же эффекта применяется какая-нибудь хитрость на стороне сервера. Примером такой хитрости является хэширование всего исходного запроса по алгоритму MD5. С исключительно высокой вероятностью значение полученной свертки будет соответствовать одному и только одному исходному запросу.
Итак, отказоустойчивая система обрабатывает последовательность запросов, поступающих от внешнего партнера. Запросы (и ответы на них) служат для решения одной или нескольких бизнес-задач.
Насколько вы склонны к риску?
Во всех этих случаях мы исходим из предположения, что для обсуждаемых приложений недопустимы расходы на знание полной истины. Следовательно, мы разрабатываем систему и в особенности приложения, выполняемые в этой системе, в расчете на то, что они, вероятно, будут предоставлять пользователям отличный сервис и время от времени будут нарушать бизнес-правила, свойственные приложениям.
Заметим, что можно иметь несколько бизнес-правил с разными гарантиями. Для некоторых операций классическая согласованность может быть предпочтительнее доступности (т.е. они будут выполняться медленнее, порождать задержку и всегда приводить к гарантированным результатам). Другие операции могут быть более "кавалеристскими". Некоторые примеры:
Локально выплачивать деньги по чеку на сумму, меньшую $10000. Если сумма чека превосходит $10000, произвести проверку с использованием всех реплик.
Планировать доставку книги "Гарри Поттер", исходя из локальной оценки наличия. В отличие от этого, для доставки одного и только одного экземпляра Библии Гутенберга требуется строгая координация!
| Основная идея состоит в том, что доступность (и ее спутники – возможность автономной работы и сокращение времени задержки) можно балансировать с классическими понятиями согласованности. Эту балансировку часто можно применять к многим разным аспектам на многих уровнях гранулярности одного приложения. |
Назад в будущее
Всякий раз, когда нам приходится искать способ реализации слабо связанного решения, мы пытаемся найти аналог из докомпьютерной эпохи. Почти всегда удается найти вдохновляющие идеи в бумажных формах, пневматической почте и формах, заполняемых в трех экземплярах.
Рассмотрим проблему потерянного запроса и ее идемпотентное решение. В прошлые годы каждая форма заполнялась под копирку в нескольких копиях, и наверху каждой копии печатался порядковый номер формы. Когда подавался запрос заказа некоторой покупки, одна копия формы сохранялась в архиве заказчика и помещалась в папку с помеченной ожидаемой датой ответа. Если форма не обрабатывалась к ожидаемому времени, заказчику следовало запросить поиск этой формы. Если найти ее не удавалось, заказ поступал на обработку повторно без каких-либо изменений во избежание путаницы во время его обработки. Например, нельзя было изменить число заказываемых товаров. Уникальный порядковый номер формы позволял гарантировать отсутствие повторной обработки одного и того же запроса.
4Мы рекомендуем классическую книгу "Zen and the Art of Motorcycle Maintenance" . Точка зрения лузера в духе дзэн-будизма помогает в компьютинге и в личной жизни...
5Этот механизм используется в течение многих лет, в том числе в некомпьютеризованых системах. Он использовался нашими прародителями на тех же основаниях, на которых мы остаиваем использование уникального идентификатора, функционально зависящего от поступающего запроса (либо являясь его частью, либо порождаясь из него). Контрольный номер (в сочетании с идентификатором банка и номером счета) – это замечательный уникальный идентификатор.
6Имеет смысл основывать решение на отношении лично к ВАМ... Это единственная информация, доступная банку в локальном режиме, и расходы будут оплачены ВАМИ с большей вероятностью, чем банком.
7В Википедии свиная грудинка описывается как нижняя часть туши свиньи, из которой делают бекон. Единицей контракта служат 20 тонн замороженной грудинки. См. .
"Операционно-центрический" подход"
Оба примера, приведенные в начале раздела, демонстрируют улавливание потребностей приложения.
В примере с корзиной покупок операции "добавить покупку в корзину" и "удалить покупку из корзины" используются для фиксации намерений пользователей, когда они добавляют покупки в корзину и удаляют их из корзины. В хранилище BLOB'ов Dynamo использование этого операционно-центрического подхода обеспечивает устойчивость к случайному чередованию версий, происходящему из-за репликации и предпочтения доступности перед согласованностью. Интересно отметить, что операционно-центрическую работу можно сделать коммутативной (при выборе правильных операций и правильной семантики), в то время как использование семантики операций чтения и записи само по себе не приводит к коммутативности.
В банковском примере операции снятия со счета и зачисления на счет обрабатываются в отдельных репликах, и затем информация о них как можно быстрее доводится до других реплик. Это тоже операционно-центрический подход, приводящий к коммутативности операций. Допущение слабо связанной обработки операций снятия со счета и зачисления на счет иногда (но редко) приводит к клирингу чека, оплату которого стоило бы отклонить. Тем не менее, во многих ситуациях это является допустимым бизнес-расходом и может быть закреплено в бизнес-правиле для слабо связанных систем.
Ослабление абстракции
OK... Тогда, может быть, сработает более свободная абстракция!
В старой модели предполагалось, что работа может производиться только в одном порядке выполнения. Классическая система баз данных, работающая в основном узле, обеспечивала изоляцию в форме "единственной системы записи" (single system of record). Эта единственная история предусматривает низкоуровневую семантику операций чтения и записи, расчитанную на "воспроизведение истории".
В нашем новом мире историю в точности воспроизвести невозможно, и мы должны принимать во внимание возможность переупорядочивания работы. Это означает, что мы не можем полностью знать точное состояние системы. Это также означает, что семантика корректности и переупорядочивания должна основываться не на свойствах системы (т.е. операциях чтения и записи), а на бизнес-операциях, поддерживаемых приложением.
В разд. 5 анализируется ряд различных аспектов асихронной установки контрольных точек и то, как это влияет на разработку приложений. Сначала будет обсуждаться влияние асинхронности на нашу возможность знать истинное состояние приложения. Затем мы рассмотрим вероятностные бизнес-правила и покажем, что асинхронная установка контрольных точек не позволяет их точно соблюдать. Мы обсудим влияние коммутативности бизнес-правил. Далее мы рассмотрим разделение работы и идемпотентные операции при наличии разделенного состояния. После этого мы проанализируем возможность выбора средств синхронной установки контрольных точек состояния, если для некоторой конкретной операции риск слишком велик. Вслед за этим мы рассмотрим, как система может справиться с непредвиденными проблемами, и когда может потребоваться человеческое вмешательство. Затем мы обсудим, каким образом асихронное соблюдение правил иногда приводит к плохим результатам. В заключение мы отмечаем, что либо нужно обеспечивать синхронные контрольные точки с резервными копиями, либо следует быть готовым к извинениям за поведение системы...
От переводчика, или Ежели где чего убудет, то в другом месте это всяко присовокупится
На самом деле, в контексте этой статьи нужно было бы толковать закон Ломоносова-Лавуазье с точностью до наоборот: "ежели где чего присовокупится, то в другом месте это всяко убудет", поскольку основной смысл статьи (как я его понимаю) состоит в том, что, в соответствии с теоремой CAP Эрика Брювера (Eric Brewer) , в одной и той же системе нельзя одновременно поддерживать свойства согласованности, доступности и распределенности. Притом, что для многих современных приложений на первом месте стоят требования доступности и распределенности, для них приходится жертвовать согласованностью (в понимании ACID-транзакционности).
Мне кажется, что в силу интуитивной доходчивости упомянутого закона этот факт сам по себе вполне воспринимается широкими кругами компьютерной общественности, но гораздо менее понятным вопросом является то, какие же распределенные и высоко доступные приложения приложения можно строить на основе систем управления данными, не поддерживающих ACID-транзакционность. И хотя бы частичный ответ на этот вопрос дает статья Хелланда и Кэмпбелла. Грубо говоря, этот ответ можно сформулировать следующим образом: отсутствие ACID-транзакционности почти всегда повышает риск того, что в некоторых ситуациях приложение не оправдает ожидания своих пользователей.
Но, с другой стороны, почти всегда такой риск имеется и при поддержке ACID-транзакционности. Любой бизнес должен быть готов к тому, что клиентам придется принести извинения. Дело разработчиков приложения – соразмерить преимущества, которые получат бизнес и его клиенты из-за повышенной доступности соответствующих услуг, и риски, возникающие из-за отсутствия ACID-транзакционности. В ряде ситуаций (и авторы приводят их примеры) эти новые риски вполне допустимы.
Отчасти статья помогает разобраться с той заменой ACID-транзакционности, которая обозначается модным в последнее время термином eventual consistency (согласованность "рано или поздно"). Наверное, наиболее важно то, что это понятие возникло не вчера и даже не позавчера.
По всей видимости, его ввел в обиход Эндрю Таненбаум (Andrew Tanenbaum), и о нем говорилось уже в изданной в 1995 г. книге Distributed Operating Systems (Prentice Hall, Englewood Cliffs, N.J., 1995). Просто теперь (в особенности, в связи с появлением "облачных вычислений" (cloud computing)) распределенность и доступность приложений стали настолько востребованными, что практически необходимо применять ослабленные модели транзакционности и согласованности.
Кстати, интересно, что и сама статья Хелланда и Кэмпбелла написана в очень неформальном, "ослабленном" стиле, вообще говоря, не свойственном большинству статей и книг, посвященных проблемам управления классическими транзакциями. Возможно, это связано с личными предпочтениями авторов, а может быть, ослабление требований к предмету исследований влечет ослабление требований к изложению результатов этих исследований. В любом случае, должен сказать, что мне этот "ослабленный" стиль не очень по душе, и я прошу прощения читателей за его сохранение в переводе (в любом бизнесе возможны извинения!). Но надеюсь, что фактическая содержательность статьи перевешивает возможные недостатки изложения.
Отказоустойчивость при наличии ACID
Для поддержки сериализуемости классические алгоритмы делают в каждый момент времени что-то одно. Все известные нам и любимые нами алгоритмы управления параллелизмом всячески пытаются добиться видимости того, что в каждый момент времени происходит что-то одно.
При анализе абстракции отказоустойчивости, описанной в разд. 2, мы видем, что во главе угла находятся синхронные контрольные точки и линейная история. Если корректность определяется в соответствии с классическими свойствами ACID, то важно обеспечить упорядоченность транзакций. И это, конечно, сериализуемость .
Интересно сопоставить пример 1 (Tandem образца 1984 г.) и пример 2 (Tandem образца 1986 г.). В примере 1 установка контрольных точек с резервной системой происходит на основе операций записи и чтения. Это корректно, но не обязательно обеспечивает высокую производительность. В примере 2 синхронизация состояния происходит при завершении транзакции. Внутритранзакционным параллелизмом управляют традиционные методы СУБД. Только после завершения транзакции требуется гарантировать, что выполненная работа переживет отказ.
с понятием отказоустойчивости когда вы
OK, посмотрим, что происходит с понятием отказоустойчивости когда вы НЕ стремитесь к сериализуемости (классические свойства ACID), а довольствуетесь новыми свойствами ACID – ассоциативностью, коммутативностью, идемпотентностью и распределенностью.
Если вы разбиваете алгоритм выполнения требуемой работы на части, то каждая часть должна быть идемпотентной (точно так же, как в базовом подходе к отказоустойчивости). Кроме того, мы считаем, что работа распределена по сети, а не сконцентрирована в какой-либо централизованной системе. Единственным способом обеспечить эту возможность при сохранении классических ACID-гарантий является использование хорошо описанных пессимистических или оптимистических механизмов управления параллелизмом. Обычно они являются взаимозаменяемыми.
Если приложение ограничивается дополнительными требованиями коммутативности и ассоциативности, мир становится ГОРАЗДО проще. Тогда не нужно больше согласовывать состояния основной и резервной систем в синхронном режиме. Можно очень пассивно относиться к совместно используемой информации. Это делает возможной автономную работу, использование медленных каналов связи, применение низкокачественных центров данных и т.д.
Как это ни удивительно, мы обнаружили, что во многих случаях бизнес-практики эти ограничения удовлетворяются. Анализ традиционных способов выполнения бизнес-операций показывает наличие многих примеров, соответствующих этому подходу. В мире баз данных мы настолько "прикипели" к абстракциям чтения и записи, что забываем в поиске новых идей смотреть на то, что и как делают обычные люди.
Поиск взаимозаменяемости
Если посмотреть на то, как функционирует компьютерный мир, можно заметить расширяющийся процесс категоризации с образованием наборов взаимозаменяемых сущностей. Вы не можете забронировать в отеле Хилтон комнату 301, но можете получить комнату для некурящих с большой двухспальной кроватью.
Взглянем теперь на свиную грудинку. При чем здесь свиная грудинка? Дело в том, что этот термин описывает целую кучу свинины. Существование грудинки как единицы фьючерсных контрактов служит мощным финансовым механизмом, поддерживающим свиноводство. Фермеры могут продовать своих свиней до того, как они достигнут кондиции, и тем самым ослаблять свои риски.
Реальный мир изобилует алгоритмами для достижения идемпотентности, коммутативности и ассоциативности. Они являются частью системы смазки бизнеса реального мира и приложений, которые мы должны поддерживать на своих отказоустойчивых платформах. Основная хитрость состоит в поиске механизмов для создания эквивалентности операций или ресурсов.
Предстоящая работа
По-видимому, было бы очень полезно проанализировать разные приложения в бизнес-среде, чтобы обнаружить повторяющиеся схемы их организации. Что за операции используются в различных приложениях? Когда они являются коммутативными? Какие приемы делают их идемпотентными? Имеются ли решения, для которых требуется лишь синтаксическая переработка для применения в разных средах? Имеется ли таксономия паттернов, к которым могут приводиться различные решения?
Наши предки были ОЧЕНЬ умны и для реализации своего бизнеса использовали слабо связанные системы. Они соединяли слабо связанные системы с использованием телеграмм, писем и почтовых систем. Для функционирования этих систем требовались переупорядочиваемые операции. Иногда одна и та же работа запрашивалась дважды, и в этих случаях требовались протоколы, поддерживающие идемпотентность. Как использовались эти схемы при прокладывании железных дорог и построении фордовских автомобилей серии Model-T? Не ждут ли эти паттерны своего использования в современных распределенных системах?
Приемлемое ослабление поведения
В 1986 г. система Tandem демонстрировала существенно лучшую производительность, чем в 1984 г. Однако могли возникать отказы процессоров, приводящие к поведению системы, отличному от поведения предыдущего ее выпуска. Если возникал отказ процессора в середине выполнения некоторой транзакции, то в предыдущем релизе выполнение этой транзакции продолжалось. В 1986 г. отказ процессора мог привести к потере выполняемых транзакций.
Хотя с технической точки зрения поведение изменилось, имелись основания считать это изменение приемлемым. С самого начала правила системы позволяли ей аварийно завершать транзакции без (видимых) причин. К аварийному завершению транзакциии могли привести синхронизационные тупики, решения операторов, срабатывание таймаутов и т.д. Поэтому это ослабление поведения системы и было приемлемым.
В версии системы Tandem 1984 г. была реализована синхронная передача данных об операции записи в резервный процесс. До установки контрольной точки приложение не получало от основного DP подтверждения о выполнении операции записи. В 1986 г. записи стали асинхронными, но гарантировалось, что после фиксации транзаций отказы процессоров не вызовут потери ее данных в дисковой памяти.
Tandem NonStop образца 1984 г.
Система Tandem NonStop – это массивно-параллельная система без использования общих ресурсов со связью между компонентами на основе обмена сообщениями . У каждого узла имеется свой центральный процессор, основная память, доступ к шинам передачи сообщений и контроллерам ввода-вывода. У каждого контроллера ввода-вывода имеются два порта, и к нему могут производить доступ любые два узла системы. Пары котроллеров ввода-вывода обеспечивали доступ к зеркальным дискам. Эта аппаратная архитектура вместе с операционной системой Guardian, монитором транзакций (Transaction Monitoring Facility, TMF) и дисковым процессом (Disk Process, DP) обеспечивала наилучшую в отрасли доступность для систем OLTP в 1980-е гг. и не утратила свое лидерство до сегодняшних дней.

Рис. 2. Аппаратная архитектура Tandem NonStop. От 2-х до 16-ти процессоров (с основной памятью и портом ввода-вывода) объединяются двухпортовой шиной передачи сообщений Dynabus. Каждый контроллер ввода-вывода подсоединяется к двум процессорам. Зеркальные диски подключаются к избыточным контроллерам ввода-вывода. Такая архитектура позволяла выдержать любой одиночный отказ.
Для выполнения своей транзакционной работы приложение запускается в одном из процессов и посылает сообщения для чтения с дисков и записи на них дисковым процессам, которые управляют данными и формируют записи для журнала транзакций. При выполнении каждой операции записи выполняется установка контрольной точки, чтобы резервный узел мог продолжить выполнение транзакции в случае отказа основного узла, обсуживающего диск. Во время фиксации транзакции от всех DP, выполнявших операции записи, требуется выталкивание их журналов в ценральный процесс дискового аудита (Audit Disk Process, ADP ).

Рис. 3. В системе Tandem образца 1984 г. алгоритм каждой операция записи процесса DP является идемпотентным. Данные об этой операции посылаются основным дисковым процессом резервному процессу при установке контрольной точки.
Следует обратить внимание на то, какова гранулярность элементов в этом подходе к отказоустойчивости. В 1984 г. каждая операция записи являлась идемпотентной, и для нее устанавливалась контрольная точка в резервном DP . Единицей гранулярности отказа был отдельный процесс или процессор. Гранулярность "идемпотентного подалгоритма" определялась одной операцией записи, которая приводила к установке контрольной точки. Отказы основного DP не обязательно вызывали аварийное завершение транзакции (рис. 4).

Рис. 4. В системе Tandem образца 1984 г. показаны процесс приложения, основной и резервный дисковые процессы (DP) и процесс дискового аудита, который записывает журнал на диск. В контрольной точке между основным и резервным DP содержатся данные об операции записи, лишь слабо коррелирующие с данными в журнале транзакций.
Tandem NonStop образца 1986 г.
В 1985 г. в составе нового выпуска операционной системы Tandem NonStop Guardian присутствовал новый дисковый процесс DP2. В этом выпуске имелся ряд изменений, включая динамическую оптимизацию стратегии отказоустойчивости .
В полностью переработанном дисковом процессе DB2 применялся совершенно новый подход к установке контрольных точек. Журнал транзакций, описывающий изменения состояния на диске, теперь использовался и для описания изменений, которые должны были стать известны резервному дисковому процессу. Другими словами, установка котрольных точек и журнализация транзакций объединялись в одном механизме. Журнал сначала отправлялся резервному процессу, а потом ADP, который записывал его на диск (рис. 5).

Рис. 5. В системе Tandem образца 1986 г. показаны процесс приложения, основной и резервный дисковые процессы (DP) и процесс дискового аудита, который записывает журнал на диск. Записи о контрольных точках DP такие же, что и содержимое журнала. Эти данные перетекают от основного DP к резервному, потом к ADP (основному и резервному) и затем записываются на диск. Заметим, что приложение получает подтверждение (2) до посылки этих данных процессом DP2 куда бы то ни было (даже пересылка данных о контрольной точке резевному DP производится асинхронно с ответом на запрос операции записи со стороны приложения).
Цель нового подхода состояла в том, чтобы позволить сохранять изменения, вызываемые транзакционной операцией записи, в транзакционном журнале в основной памяти основного дискового процесса DP2. Основной DB2 подтверждал приложению выполнение операции записи. Конечно, оставался открытым вопрос о корректности такого поведения, если в результате отказа основного DP2 терялись буферизованные изменения, произведенные незафиксированными (uncommitted) операциями записи. Как это могло быть корректным?
Корректность обеспечивалась за счет того, что при отказе основного DP система аварийно завершала все выполняемые транзакции, которые использовали этот процесс. Поскольку для всех зафиксированных транзакций система гарантировала выталкивание всех изменений в дисковую память, потеря содержимого основной памяти основного DP влияла только на незавершенные тразакции.
Поскольку система при отказе основного DP автоматически аварийно завершала все соответствующие транзакции, корректность соблюдалась.
Эта схема означала, что отказ процессора мог привести к аварийному завершению большего числа транзакций. Это случалось очень редко и не противоречило общим правилам системы, допускающим аварийное завершение транзакций без повода с их стороны. Вполне возможно, что это изменение системы было почти незаметным для разработчиков приложений и пользователей.
Новая схема обеспечила громадный выигрыш в производительности. Операцию записи в DP2 стало можно выполнять без пересылки информации о контрольной точке резервному дисковому процессу. Это позволило существенно сократить расходы центрального процессора и в еще большей степени уменьшить задержки, поскольку приложению не требовалось ждать завершения операции установки контрольной точки для получения подтверждения выполнения своей операции записи. Буфер, содержащий журнальные записи, передавался резервному процессу (и ADP) лишь периодически. Это очень напоминает групповую фиксацию (group commit) . Легко понять, откуда берется эффективность, если подумать о различии между индивидуальным автомобилем, раскатывающим по городу с одним водителем, и городским автобусом, через каждые пять минут высаживающим и всаживающим пассажиров. Как отмечалось в , в нормальных обстоятельствах ожидание участия в совместном использовании буферов записи может сократить задержку, поскольку уменьшается общий объем работы системы. Это сокращение объема работы может уменьшить коэффициент загруженности системы и более чем компенсировать возможные потери транзакций.

Рис. 6. В Tandem образца 1986 г. каждая операция записи локально буферизуется в основном DP. НЕ ГАРАНТИРУЕТСЯ, что данные об этой операции будут переданы резервному процессу, и отказ основного процесса приводит к аварийному завершению транзакции. Гарантируется выталкивание на диск журнала транзакции при ее фиксации. Теперь алгоритм операции записи не является идемпотентным, в качестве такого алгоритма теперь выступает транзакция.
Если вернуться к абстракции отказоустойчивости, то мы видим (рис. 6), что гранулярность идемпотентного алгоритма увеличилась от размера операции записи до размера транзакции. Гранулой отказа по-прежнему является процессор, и пользователь почти не ощущает изменения общего алгоритма.
доставка журнала
Этот пример должен быть хорошо известен большинству пользователей. В классической системе баз данных имеется некоторый процесс, который читает журнал и доставляет его в резервный центр данных. При обычной реализации этого механизма транзакции фиксируются в основной системе (и пользователю подтверждается выполнение запроса фиксации), и журнал доставляется асинхронно. Резервная система баз данных воспроизводит журнал, постоянно нагоняя основную систему.
Обычно приложения и пользователи не обращают внимания на доставку журнала. Пока не возникают отказы, приложение и пользователь сыты, глупы и счастливы. Когда же отказ СЛУЧАЕТСЯ, некоторые недавно завершенные транзакции теряются, когда резервная система берет на себя управление.
Это означает, что абстракция отказоустойчивости, описанная в разд. 2, перестает работать, если состояние не становится немедленно известным резервной системе. Отказоустойчивость НЕ является прозрачной. ВОЗМОЖНА (с низкой вероятностью) полная утрата недавно завершенной работы.
Чтобы обеспечить прозрачную отказоустойчивость центра данных, алгоритм отправки журнала должен был бы притормозить отправку ответа приложению на запрос фиксации транзакции до тех пор, пока в основной системе не станет известно, что журнал действительно доставлен в резервную систему. В большинстве случаев такая задержка недопустима, и приходится работать при наличии небольшой вероятности утраты результатов недавно завершенной работы. Изменение синхронной передачи состояния на асинхронную передачу является интересным ослаблением нашей базовой абстракции, и это еще один пример ситуации, в которой стоимость поддержки "согласованности на некотором расстоянии" является слишком высокой, как если бы попытаться использовать протокол двухфазной фиксации для координации менеджеров ресурсов.
| Доставка журнала: наш первый пример, в котором небольшое жертвование согласованностью приводит к значительному выигрышу в устойчивости и масштабировании! |
Shopping Cart и Dynamo
Система хранения данных Dynamo используется для поддержки корзин покупок и других систем компании Amazon. Dynamo – это реплицированное хранилище BLOB'ов, реализованное с применением динамической таблицы хэширования (Dynamic Hash Table, DHT). Dynamo представляет интерес во многих отношениях, включая сознательный выбор поддержки доступности в ущерб согласованности. Dynamo всегда принимает операции PUT, даже если это приведет к получению более поздними операциями GET несогласованных данных.
В взаимодействие приложений с системой Dynamo основывается на интерфейсе PUT и GET. Из-за аномалий репликации операция GET может возвращать устаревшую информацию. Выполнение операции PUT над этой устаревшей информацией может приводить к образованию параллельных версий. Более поздняя операция GET над тем же BLOB'ом может вернуть две версии, происходящие от одной и той же версии BLOB'а, или две "двоюродные" версии, и приложение Shopping Cart должно их согласовать. Система Dynamo, действующая, как основа хранения данных, может возвращать в ответ на GET две или большее число старых версий. Последующая операция PUT должна записать версию того же BLOB'а, в которой интегрируются и согласовываются все предыдущие версии.
Для обеспечения возможности интеграции версий на уровне приложения Shopping Cart должно регистрировать операции наподобие того, как это делается в бухгалтерской книге. Операция удаления из корзины некоторого товара регистрируется как операция добавления к корзине. Эти операции "ADD-TO-CART", "CHANGE-NUMBER" и "DELETE-FROM-CART" обычно можно согласовать, когда они, в конце концов, собираются вместе. Очень редкие аномалии в Shopping Cart являются приемлемыми, поскольку заказ посетителя магазина проверяется в течение процедуры его оформления. Недоступность услуги корзины покупок обходилась бы Amazon очень дорого, поскольку это приводило бы к упадку бизнеса и неудовлетворенности пользователей.
Dynamo является основой хранения данной, независимой от приложения Shopping Cart, которое на нем базируется. В ответ на операцию GET Dynamo возвращает некоторый BLOB (а иногда два или большее число BLOB'ов). Если возвращается более одного BLOB'а, приложение должно согласовать версии И записать результат при помощи следущей операции для той же корзины. Приложение Shopping Cart может это сделать за счет представления содержимого корзины в виде набора операций. Уникально идентифицируемые операции над покупками можно объединить в список с предсказуемым результатом. Это является ключом к коммутативности операций над корзиной покупок. В свою очередь, коммутативность используется для достижения исключительно высокого уровня доступности.
банковские счета и книги счетов
Имеются основания для наличия на чеках контрольных номеров. Контрольный номер (в сочетании с идентификатором банка и номером счета) обеспечивает уникальный идентификатор. За исключением ошибочных ситуаций (и/или случаев мошеничества) получатель средств по данному чеку и сумма этих средств являются неизменными. Чек поступает в банковскую систему с известным уникальным идентификатором, и участники слабо связанного процесса совместно используют информацию в том, что можно было бы считать постоянным потоком работ.
Вы депонируете в своем банке чек своего шурина на $100, и, поскольку вы являетесь хорошим клиентом, деньги нисколько не задерживаются. Остаток на вашем счете увеличивается с $1000 до $1100. Информация о вашем банковском счете ассоциируется с чеком. Чек отсылается в банк вашего шурина. Позже, если чек возвращается в связи с отсутствием средств на счете шурина, с вашего счета снимется $130 (исходные $100 плюс $30 за отказ оплаты чека). Интересно, что решение об оптимистическом развитии событий основано на хорошем отношении банка лично к ВАМ. Для менее надежного клиента (такого, например, как ваш шурин) зачисление денег на счет было бы задержано (резервирование на случай потенциального отказа оплаты счета).
Операции зачисления денег на счет и снятия их со счета коммутативны. Имеется четкое бизнес-правило, что остаток на счету не должен снижаться ниже нуля. Если бы вы потратили $1100 до возврата чека своего шурина, состояние вашего счета нарушило бы это бизнес-правило, когда чек был отклонен из-за отсутствия денег на счете шурина. Политика банка делает это менее вероятным, но не невозможным. Бизнес-решение банка состоит в том, чтобы допускать подобные риски.
Рассмотрим также учетную книгу, связанную с банковским счетом. В конце каждого месяца выпускается выписка по счету. Не требуется, чтобы она была абсолютно точной. Какой-либо чек, выпущенный в полночь 31-го числа данного месяца, может попасть в выписку как этого, так и следующего месяца. Учитываются поступления на счет и снятия со счета.
Выпущенная выписка является постоянной и неизменной. Ошибки в мартовской выписке могут быть исправлены в апрельской выписке, но мартовская выписка никогда не изменится.

Рис. 7. В упрощенной схеме обработки имеются два основных аспекта: (1) запоминание всего, что встречается, и (2) принятие решение о том, не следует ли отклонить оплату чека.
При работе со счетом банк должен выполнить два действия (рис. 7). Во-первых, на основе знания о состоянии счета требуется решить, следует ли произвести клиринг чека. Во-вторых, нужно педантично запоминать все операции (снятия и зачисления), выполняемые над данным счетом.
Представим себе реплицированную банковскую систему, в которой имеются две (или более) копии некоторого банковского счета, и над каждой копией может производиться клиринг чеков. Имеется небольшая (но реальная) вероятность того, что в результате предъявления нескольких чеков в разные реплики произойдет овердрафт, который не удастся выявить к моменту отклонения оплаты одного из чеков. В каждой реплике, производившей клиринг чеков, будет запомнен соответствующий чек вместе со своим контрольным номером. Если допустить, что ни одна реплика не утратит жизнеспособность слишком надолго, то вскоре информация о каждом чеке будет добавлена к банковской выписке, и будут выделены требуемые средства. В случае длительной утраты работоспособности реплики данные об операциях с чеком войдут в выписку следующего месяца, но это не слишком важно.
В этой банковской системе информация о чеках объединяется, когда реплики обмениваются данными. Использование контрольных номеров делает обработку чека идемпотентной. Природа операций (добавление и уменьшение) обеспечивает коммутативность И ассоциативность этих действий.
ОЧЕНЬ вероятно, что банковская система, основанная на ненадежных компьютерах без фальшполов, операторов и систем резервного питания, оказалась бы более экономически эффективной, чем дорогостоящая централизованная система. Как показано выше, разделение работы на запоминания, предположения и извинения – это ровно то, как сегодня работают банки.
Пример с бронированием мест
В некоторых транзакциях реального мира вовлекаемые в них ресурсы нельзя считать взаимозаменяемыми. Одним из хороших примеров является бронирование мест в зрительном зале на концерт, когда на принятие решений о покупке серьезно влияет наличие реальных мест. Наличие хороших свободных мест в зрительном зале является важным как для поставщика, так и для потребителя. Одним из способов реализации корректного приложения, поддерживающего то бизнес-правило, что любое место в зрительном зале должно быть либо "доступно для бронирования", либо "занято и связано с некоторым достоверным актом приобретения билета", является использование транзакции базы данных для поддержки этого бизнес-правила. Эта схема работает только в том случае, когда имеется доверенный агент, управляющий приобретением билетов. Такие агенты контролировали бы транзакции и резервировали бы доступные места. Если покупатель отказывается от билета, транзакция откатывается, и места снова становятся доступными для бронирования.
В ситуациях онлайновых покупок, которые контролируются потребителем, транзакции изменяются и в пространстве, и во времени, и наша система продажи билетов приходит в неработоспособное состояние. Во-первых, что касается пространственного измерения, потребитель не является доверенным агентом. Наша транзакция теперь выходит за пределы границ доверия, установленные для системы бизнес-правилом. Во-вторых, что касается временного измерения, мы не можем ограничить время, в течение которого недоверенные агенты могут удерживать нашу систему в несогласованном состоянии. В этом конкретном примере недоверенные агенты могли бы использовать эти аспекты системы для того, чтобы быстро начать транзакции над наилучшими местами, слелать их недоступными для других потребителей, а затем выгодно их перепродать. Места, билеты на которые не проданы таким недобросовестным агентом, можно было бы вернуть в систему, просто откатив соответствующие транзакции, без каких-либо затрат со стороны агента.
Каждый, кому приходится приобретать билеты в режиме "онлайн", узнает здесь ситуацию "бронирования мест", в которой вы можете выявить наличие свободных мест, а затем в течение ограниченного периода времени (обычно нескольких минут) должны завершить транзакцию. Если транзакция не завершается успешным образом в течение этого времени, места снова помечаются, как "доступные". Это делается за счет использования трех состояний мест:
{"доступное"}
{"ожидающее покупки билета", идентификатор сессии}
{"купленное", идентификатор покупателя}
Для перевода мест из одного состояния в другое (в том числе, для возвращения в состояние "доступное" места, слишком долго ожидавшего покупки) используются отдельные транзакции базы данных.
В этом примере подход к распределению ресурсов ближе к "гарантированному выделению". Места считаются уникальными, и требуется координация основной и резервной системы для обеспечения консервативного (т.е. гарантированного) управления ресурсами. Чтобы избежать этой проблемы, нужно создавать пулы ресурсов.
Прозрачная отказоустойчивость
Отказоустойчивые системы состоят из многих компонентов, и целью разработки такой системы является поддержка продолжения ее функционирования при отказе одного компонента (а иногда и нескольких компонентов). В этом обсуждении мы не касаемся "византийских отказов" , когда некоторый компонент может вести себя ошибочным образом (а в задаче византийских генералов – потенциально злоумышленно). Здесь имеется в виду "быстрое проявление сбоев" ("fail fast") , когда компонент либо функционирует корректно, либо просто перестает работать В сценариях быстрого выявления сбоев не учитывается возможность неправильно работающих компонентов. Кроме того, не ставится вопрос о том, что случится, если какой-либо компонент станет работать настолько медленно, что посеет хаос в системе. В этом обсуждении мы будем обсуждать проблемы, возникающие даже при упрощающих предположениях о быстром проявлении сбоев.
Мы обнаружили, что в ряде случаев отказоустойчивый алгоритм разбивается на идемпотентные подалгоритмы (рис. 1). Собирая достаточную информацию между идемпотентными шагами и посылая ее на границах отказов, алгоритм в целом может сохранить рабоспособность системы в случае отказов ее компонентов.
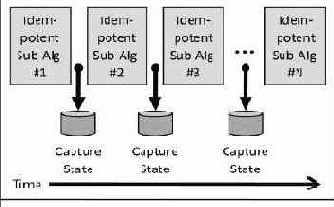
Рис. 1. Разбиение отказоустойчивого алгоритма на несколько подалгоритмов, каждый из которых является идемпотентным. За счет фиксации состояния подалгоритмов и обеспечения доступа к нему после сбоев основной алгоритм выдерживает отказы.
Это напоминает переправу через реку вброд, когда человек шагает с одного камня на другой, всегда удерживая одну ногу на надежной опоре. Важно добиться такой линейной последовательности шагов, которая привела бы, в конце концов, на другой берег реки (т.е. позволила бы выполнить требуемую работу).
Оказывается, во многих отказоустойчивых системах именно этот метод используется, чтобы сделать отказы прозрачными для приложений и пользователей. Мы рассмотрим некоторые примеры таких систем.
Синхронные контрольные точки ИЛИ извинения!
Итак, в разд. 5 мы отмечаем, что имеются следующие варианты разработки:
вы можете использовать сихронные контрольные точки и подвергать пользователей задержкам, или
вы можете использовать асинхронные контрольные точки, снижать время задержек и иметь дело с измененной семантикой приложений.
Эта измененная семантика означает, что вам не всегда известна точная истина, поскольку работу может перехватить партнер. Она означает, что может потребоваться понимание вероятностной природы соблюдения бизнес-правил и возможности переупорядочивания операций. Тем не менее, имеется вариант применения бизнес-критериев (например, наличие чека на сумму больше $10000), которые вызывают применение синхронной установки контрольных точек. Кроме того, полностью приемлемо допущение человеческого вмешательства в разрешение некоторых проблем, если это происходит настолько редко, что не противоречит соображениям экономеческой целесообразности.
Коротко говоря, выбор этих вариантов зависит от их значимости для бизнеса.
3Искушенный читатель поймет, что при этом проблема идемпотентности перемещается в сообщение, поступающее от клиента в точку входа. Повторные посылки одного и того же сообщения приводят к тому, что его обработкой начинают заниматься несколько разных реплик. Если у этой работы нет побочных эффектов (например, если она сводится к чтению каких-либо данных), то ее можно без проблем выполнить несколько раз. Если же работа производит побочные эфффекты, то обычно для исключения ее дублирования производится координация на основе куки (cookie) или идентификатора пользователя.
Для исключения повторной обработки идентификатор запроса должен функционально зависеть только от запроса в понимании серверной системы. Это возможно, если уникальный идентификатор генерируется вне сервера (например, контрольный номер (check number), обсуждаемый в подразделе 6.2), или если сервер вычисляет его некоторым предсказуемым образом (как это обсуждалось в подразделе 2.1).
Согласованность "рано или поздно" и хранение данных
Интересно, что значительная часть публикаций, посвященных согласованности "рано или поздно", фокусируется на семантике операций чтения и записи. Например, в недавней статье Вернера Фогельса (Werner Vogels) разъясняются многие понятия из области согласованности "рано или поздно", но обсуждение ведется в контексте клиентов, систем хранения данных и операций модификации.
В статье про Amazon Dynamo затрагивается много интересных тем и показывается, каким образом в Dynamo сохраняются BLOB'ы с доступом к значениям по ключу. Кроме того, в подразделе 4.4 про версии данных обсуждается использование операций "добавить покупку в корзину" и "удалить покупку из корзины" и то, как эти операции фиксируются в BLOB'ах, хранение которых поддерживает Dynamo. Даже если истории версий переупорядочиваются, покупки, добавленные в корзину, не будут потеряны, если только соответствующая версия BLOB'a не откажет вместе с другими версиями. Случайно удаленные покупки появятся снова.
Системы хранения сами по себе не могут обеспечить коммутативность, требуемую для создания устойчивых систем, функционирующих с применением асинхронных контрольных точек. Для обеспечения возможности переупорядочивания нужны бизнес-операции. Система Dynamo не делает этого сама по себе. За семантику согласованности "рано или поздно" и коммутативность отвечает приложение Shopping Cart, работающее поверх системы хранения Dynamo.
По мнению авторов, настало время отказаться от изучения согласованности "рано или поздно" в терминах операций модификации и систем хранения. Реальные результаты удается получить только при исследовании семантики операций уровня приложения.
Согласованность "рано или поздно" и приложения
В обоих приведенных выше примерах уникально идентифицируемая работа поступает в систему и обрабатывается одной из ее реплик. Эта работа распространяется в другие реплики, когда с ними имеется связь.
Поскольку запросы коммутативны (т.е. могут быть переупорядочены), их можно обрабатывать в разных репликах и в разных порядках. Очень велика вероятность, что при этом будут получены одни и те же результаты. Кроме того, при разработке каждой системы применяется бизнес-политика для обработки ситуаций, когда разные порядки выполнения приводят к разным результатам.
Сохранение прозрачности при разрастании системы
В этом разделе мы обсудим, как была реализована прозрачная отказоустойчивость в системе Tandem NonStop за счет использования синхронных контрольных точек на границе отказов. Сначала мы рассмотрим систему Tandem образца 1984-го г., когда стратегия установки контрольных точек предполагала пересылку состояния при выполнении каждой отдельной операции записи в базу данных. Эта стратегия была корректной, но приводила к некоторым проблемам производительности. Около 1985-го г. программное обеспечение было модифицировано применительно к новой стратегии, которая обеспечивала более высокую производительность. Поэтому далее мы проанализируем поведение систем Tandem образца 1986-го г., когда сохранение состояния производилось менее энергично, но этого хватало для обеспечения гарантированной прозрачности. Мы завершим разд. 3 обсуждением того соображения, что изменения в системе периода 1984-1986 гг. ослабляли семантику отказов, но эти ослабления являлись приемлемыми на практике.
Транзакции и идемпотентность
Транзакции ОБЛЕГЧАЮТ построение идемпотентных подалгоритмов. Атомарные транзакции... атомарны и не раскрывают частичные результаты. За счет использования транзакций снимаются многие (но не все) проблемы обеспечения идемпотентного поведения. Остается всего лишь обеспечить либо чтобы выполнение одной работы никогда не производилось более одного раза, либо чтобы при второй попытке выявлялось наличие первой успешной попытки, и никакие действия не производились. Некоторые примеры будут приведены позже.
1Более точно, данные содержатся в точности на одном узле, если мы игнорируем потребность в репликации на уровне ниже уровня разделения... более подробно об этом см. ниже.
Управление ресурсами с применением асинхронности
В этом разделе обсуждаются особенности управления ресурсами при асинхронной установке контрольных точек, а также возможность независимой и потенциально избыточной работы. Сначала мы обсудим распределение ресурсов в слабо связанных системах, и следует ли обеспечивать их избыточное (over-booked) или же гарантированное (over-provisioned) резевирование. После этого мы отметим, что при наличии аварийных ситуаций или других ошибок компьютерные оценки не обязательно отражают состояние реального мира. Далее мы рассмотрим пример консервативного (гарантированного) подхода к распределению ресурсов в системах бронирования мест (seat-reservation). Затем мы проанализируем преимущества однородности (взаимозаменяемости) ресурсов в тех ситуациях, когда это возможно. После этого мы обсудим использование уникальных идентификаторов при обработке асинхронных запросов. Вслед за этим мы проанализируем связь согласованности "рано или поздно" и асинхронного управления ресурсами. В заключение раздела мы рассмотрим паттерны, использовавшиеся в бизнесе до появления компьютеров, и их использование при разработке слабо связанных систем.
В конце концов мы поговорим и станем согласованными
Когда отсоединенные реплики работают независимо, они накапливают операции. Это схоже с тем, как реплика обработчика банковского счета производит клиринг одних чеков, но не других. Это также схоже с тем, как в BLOB'е, управляемом Dynamo, сохраняются результаты некоторых операций над корзиной покупок (например, "Добавить в корзину" и "Удалить из корзины"), а результаты других операций отсутствуют из-за временных соотношений управления версиями.
Когда работа нескольких реплик сливается, создается новый, более точный ответ. Если приложение разрабатывается в расчете на поддержку согласованности "рано или поздно", требуется обеспечить, чтобы порядок поступления работ в любой узел не оказывал определяющего влияния на результат. Реплики, которые видят одну и ту же работу, должны видеть один и тот же результат независимо от порядка поступления этой работы.
Как отмечалось выше, иногда операции, накопленные разными репликами, приводят к нарушению бизнес-правил приложения. В результаты работы независимых реплик, производящих клиринг чеков для одного и того же банковского счета, скорее обнаружится чек с отклоненной выплатой, чем будет обработано слишком много чеков при наличии достаточных средств на счету. Подобные нарушения бизнес-правил должны учитываться разработчиками приложений, которые должны оценить степень риска на основе верятностного анализа.
Важность уникальных идентификаторов
Одним из важных паттернов при управлении асинхронностью является использование уникальных идентификаторов при отслеживании запросов в распределенной системе. Иногда чрезмерно усердные реплики будут сначала обрабатывать какие-либо запросы, а лишь потом обнаруживать, что эта работа была повторной. Если при этом был выделен какой-либо взаимозаменяемый ресурс, система должна это выявить и вернуть его. Выявление избыточной работы становится возможным за счет наличия уникального идентификатора запроса.
Таким образом, при рассмотрении темы управления ресурсами при наличии асинхронности мы видим важность наличия уникально идентифицируемых ресурсов, что позволяет нам добиться идемпотентного поведения.
Вероятностные бизнес-правила
При наличии асинхронной установки контрольных точек появляются временные промежутки (окна) такие, что если в этом промежутке времени происходит сбой, то уже выполненная работа может быть потеряна или отложена. Если отказывает основная система, то внутри нее может остаться завершенная работа, данные о которой еще не были переданы в резервную систему. Эта работа либо теряется, либо откладывается (т.е. воспроизводится после восстановления работоспособности бывшего основного узла).
Если в основной системе используется асинхронная установка контрольных точек, и к поступающей от приложения работе применяется некоторое бизнес-правило, то это правило необходимо является вероятностным. Основной системе, независимо от ее намерений, не может быть точно известно, сохранит ли она работоспособность для поддержки бизнес-правил.
В тех случаях, когда резервная система, участвующая в соблюдении этих бизнес-правил, асинхронным образом связывается с первичной системой, соблюдение правил неминуемо становится вероятностным!
Анализ затрат и результатов показывает, что выгода от сокращения задержки при асинхронной установке контрольных точек перевешивает возможные потери из-за неприменения бизнес-правил, обобщающих отказоустойчивый алгоритм.
| Распределенность + асинхронность → вероятности обеспечения применения правил |
Мы наблюдаем появление приложений, в которых разобщенность еще больше увеличивается для достижения экономической выгоды от слабо связанного параллелизма и автономной работы. В таких приложениях меньше задержек, больше параллелизма и доступности. Зато они чаще делают ошибки и позже устаняют беспорядок. Иногда это идет на пользу!
Волнения и жалобы (но не слишком частые)
И что же делать, если при работе приложения ДЕЙСТВИТЕЛЬНО нарушаются бизнес-правила? Обычно приложения разрабатываются таким образом, чтобы вероятность таких нарушений была мала (поскольку они вызывают существенные эксплуатационные расходы). Но, тем не менее, рано или поздно это случится!
Справляться с нарушениями бизнес-правил лучше всего следующим образом:
послать информацию о возникшей проблеме заинтересованному человеку (по электронной почте или как-нибудь еще);
если это слишком расточительно, написать некоторое специализированное для данной области бизнеса программное обеспечение, позволяющее снизить вероятность возникновения подобных проблем.
Хотя такой подход может показаться слишком упрощенным, именно ему следуют разработчики приложений, наталкиваясь на проблемные ситуации. Это также говорит о том, что при отсутствии обобщений бизнес-правил, возможности обеспечения коммутативности бизнес-операций и бизнес-сложностей, вызываемых работой чрезмерно усердных приложений, невозможно говорить с бизнесом о последствиях проблем, вызываемых нарушением бизнес-правил, или о каких-либо компенсационных действиях.
Имеется интересная связь между отказоустойчивостью,
Имеется интересная связь между отказоустойчивостью, возможностью систем работать в автономном режиме (offlineable system) и согласованностью "рано или поздно" на основе приложений. Когда мы пытаемся выполнять крупномасштабное приложение, опирающееся на использование многих систем, мы не можем допустить задержки из-за ожидания синхронизации резервной системы с системой, действительно выполняющей работу. Это приводит к тому, что серверные системы становятся похожими на автономные клиентские приложения, поскольку им неизвестно истинное положение вещей. В свою очередь, эти основанные на использовании серверов приложения разрабатываются таким образом, что их намерения регистрируются, и работа разделяется между репликами. В правильно разработанном приложении это приводит к поведению системы, приемлемому для бизнеса, но при этом устойчивому к возрастающему числу отказов.
Эта статья начинается с анализа понятий отказоустойчивости. Вводится абстракция отказоустойчивой системы. В разд. 3 обсуждается, каким образом отказоустойчивые системы ранее обеспечивали возможность выживания приложений после отказов без каких-либо специальных действий со стороны приложений за счет синхронной установки контрольных точек, когда состояние приложения передавалось резервной системе. В разд. 4 мы начинаем рассматривать, что произойдет, если мы не сможем допустить наличие задержек, связанных с синхронной установкой контрольных точек с передачей состояния резервной системе, а вместо этого сделаем операцию установки контрольной точки асинхронной. В разд. 5 более глубоко обсуждаются способы модификации приложений с сохранением их семантики, так что допускается асихронная установка контрольных точек с пересылкой состояния приложения резервной копии. В разд. 6 приводится несколько примеров приложений, демонстрирующих корректное поведение, при котором допускаются откладывание (т.е. асинхронность) при установке контрольных точек с резервной системой. В разд. 7 обсуждается управление ресурсами в ситуации, когда порядок операций может изменяться по причине асинхронности. В разд. 8 изучается связь между этой разновидностью согласованости "рано или поздно" и теорией CAP (Consistency, Availability, and Partition-tolerance – согласованность, доступность и устойчивость к разделению). Наконец, в разд. 9 мы рассматриваем некоторые направления будущих исследований.
и отказоустойчивых систем. Как видно,
Мы рассмотрели кое-что из эволюции высокодоступных и отказоустойчивых систем. Как видно, все надежные системы строятся в виде некоторого набора ненадежных компонентов, которые соединяются таким образом, что система может продолжать полезно функционировать при отказах некоторых из этих ненадежных компонентов. С течением времени размер единицы сбоя становился все больше и больше.
Многие годы технология построения отказоустойчивых систем обеспечивала их строгое транзакционное поведение за счет синхронной установки контрольных точек на границах отказов. По мере возрастания размеров единицы отказа задержки, вызываемые операцией установки контрольных точек, выросли настолько, что стали обременительными.
В ответ на увеличивающийся размер задержки стали использовать асинхронную передачу состояния на границах отказов. Для этого потребовались новые модели и паттерны разработки приложений.
Мы постарались описать паттерны, используемые во многих современных приложениях для борьбы с отказами в территориально распределенных системах. Для обеспечения успешного выполнения приложений поверх хаоса распределенного мира требуются возможности переупорядочивания и повторяемости работ. Разработчики приложений интуитивно тяготеют к миру согласованности "рано или поздно" (обычно без использования формализмов, которые могли бы помочь им добиться успеха).
Наконец, мы проанализировали эти идеи, принимая во внимание теорию CAP, и показали, что в этом новом мире многие решения разрабатываются в расчете на некоторое ослабление классической согласованности для поддержки доступности и устойчивости к разделению. Это ослабленное понятие согласованности очень полезно и заслуживает больших академических исследований.
Запоминания, предположения и извинения
Можно утверждать, что весь компьютинг в действительности распадается на три категории: запоминания, предположения и извинения . Идея состоит в том, что все делается в локальном режиме с применением некоторой части глобального знания. Вы знаете, что вы узнаете, когда выполнится некоторое действие. Поскольку вы обладаете только частью знания, ваши действия на самом деле являются только предположениями. При подключении знаний какой-либо реплики может возникнуть очень неприятная ситуация. Согласование действий реплики и ее двойника может привести к пониманию, что требуется расчистка завала. При этом может возникнуть потребность в извинении за поведение основной системы (или ее реплики).
Итак, рассмотрим три эти аспекта:
Запоминания: Ваша локальная реплика видит то, что видит, и (следует надеяться) запоминает это. В стоимость распространения этого знания входят сетевые и вычислительные расходы, а также расходы, вызываемые задержкой ответа (в том случае, когда вы ожидаете потверждение от резервной системы на свою операцию запоминания).
Предположения: Всякий раз, когда в приложении предпринимается некоторое действие на основе локальной информации, это действие может оказаться ложным. Так случается в системах с доставкой журнала, где действие журнализуется локально, и имеется только высокая вероятность получения журнала резервной системы до отказа основной системы и перехвата управления. Поэтому предположение об обоснованности действия можно считать разумным, но нельзя считать его бесспорным. В любой системе, допускающей отход от абсолютной истины, бесспорность действия можно только предполагать. Качество этого предположения зависит от требований бизнеса.
Извинения: Если вы совершаете некоторую ошибку (из-за аномалий репликации или из-за того, что Федеральное управление гражданской авиации запретило полеты ваших самолетов, и вы не можете выполнить свои обязательства перед пассажирами, забронировавшими на них места), вы приносите свои извинения. Потребность в извинениях возникает в любом бизнесе. Как отмечалось выше, извинения перед клиентами за работу программного обеспечения, приведшую к бизнес-проблемам, могут отправляться вручную. В качестве альтернативы, некоторые извинения могут генерироваться специально разработанным кодом приложения, а при возникновении заранее непредусмотренных "нехороших" ситуаций пользователям направляется просьба о помощи.
В слабо связанном мире, в котором доступность предпочтительнее согласованности, весь компьютинг лучше всего представлять как состоящий из запоминаний, предположений и извинений.
